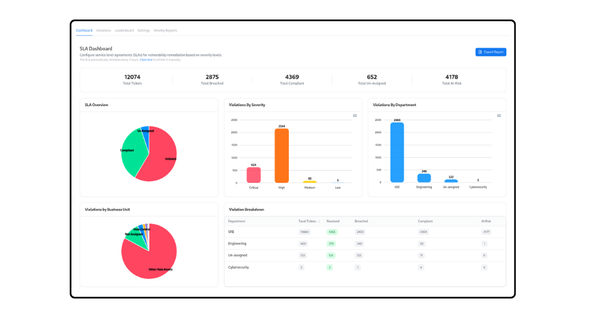
Promptware Kill Chain: The Malware Playbook Is Coming for LLMs

Large language models are no longer experimental tools. They sit inside customer support systems, developer workflows, autonomous agents, internal knowledge bases, and even financial and operational pipelines. In many organizations, LLM-powered systems now make decisions, trigger actions, and interact with other services automatically.
That shift has quietly created a new class of security risk.
What the industry often dismisses as “prompt injection” is no longer a single trick or malformed input. Researchers are increasingly observing structured, multi-stage attack campaigns against LLM systems that closely resemble traditional malware operations. This emerging threat category is now being described as promptware—malicious logic designed to exploit AI systems across multiple phases of execution.
Understanding this shift requires abandoning the idea that AI attacks are one-off prompt abuses. Instead, they must be analyzed the same way we analyze malware: as kill chains.
From Prompt Injection to Promptware
Early discussions around LLM security framed prompt injection as a novelty—clever wording that tricks a model into ignoring instructions. That framing is now dangerously outdated.
Modern attacks don’t stop at getting a model to say something unintended. They aim to:
- Bypass safety constraints
- Persist across sessions
- Spread through connected systems
- Execute real-world actions
In other words, they behave like malware.
Researchers have demonstrated that LLM-based systems can be compromised in sequential stages, with each phase building on the previous one. This mirrors decades-old attacker playbooks used in endpoint, network, and cloud compromises.
The Promptware Kill Chain
The promptware kill chain adapts classic intrusion models to AI-native environments. Each phase presents its own detection and prevention opportunities.
Initial Access
Attackers introduce malicious instructions through direct user input or indirectly through poisoned content. This often occurs via documents, emails, webpages, or API responses that the LLM is designed to retrieve and trust. The model doesn’t “download malware”—it reads it.
Privilege Escalation
Once malicious instructions are processed, attackers attempt to bypass alignment and safety controls. Techniques include role manipulation, obfuscated language, indirect task framing, and adversarial suffixes that reliably degrade safety across multiple models. This stage is functionally equivalent to escaping a sandbox.
Persistence
This is where promptware becomes significantly more dangerous than simple injection.
Instead of registry keys or startup scripts, promptware persists by embedding itself into:
- Retrieval systems (knowledge bases, emails, ticketing platforms)
- Agent memory or long-term context stores
Some payloads activate only when specific queries are made. Others execute on every interaction. At this point, the model is no longer just vulnerable—it is infected.
Lateral Movement
LLM-powered agents rarely operate in isolation. They connect to calendars, email systems, CRMs, cloud APIs, internal tools, and payment workflows. Promptware leverages these integrations to propagate instructions, leak data, or compromise additional agents—often without direct user involvement.
Self-propagating attacks, such as LLM-based email worms, demonstrate how quickly this stage can escalate across organizations.
Execution and Impact
The final phase looks less like “AI misbehavior” and more like full-scale compromise. Promptware has been shown to:
- Exfiltrate sensitive data
- Send phishing emails automatically
- Manipulate smart devices
- Trigger unauthorized transactions
- Alter operational workflows silently
At this point, the AI system becomes an attacker-controlled automation engine.
Why This Changes AI Security Entirely
The key insight of the promptware model is simple but profound:
LLMs are not just targets - they are execution environments.
Once compromised, they can reason, adapt, retrieve context, and act across systems at machine speed. Traditional security assumptions break down because:
- Payloads are linguistic, not binary
- Persistence is contextual, not file-based
- Lateral movement is API-driven, not network-based
Defensive controls that focus only on input validation or output filtering miss the larger picture.
Detection and Defense Implications
Promptware forces security teams to rethink where controls live.
Effective defenses must consider:
- Trust boundaries in retrieval pipelines
- Memory and context integrity
- Agent permissions and action scope
- Change detection in prompts, tools, and behavior
- Separation between reasoning and execution
Most importantly, AI outputs must be treated as untrusted input—especially when they trigger downstream actions.
The Bigger Picture
Promptware represents the convergence of AI systems and classic cyber offense. It borrows techniques from malware, social engineering, supply-chain attacks, and automation abuse—then amplifies them through LLM capabilities.
This is not a future problem. It is already happening.
Organizations deploying AI agents without kill-chain thinking are repeating the same mistake made in early cloud adoption: assuming new technology invalidates old attacker behavior. It doesn’t. It reshapes it. Understanding promptware as malware is the first step toward defending against it.
Ignoring that reality will simply give attackers a new platform to automate what they already know how to do.
Centralise your Appsec
A single dashboard for visibility, collaboration, and control across your AppSec lifecycle.
Explore Live Demo